I’ve been circling around this topic for a while looking for solutions that don’t eat up a serious amount of gpu memory, cpu cook or gpu cook.
My issue isn’t reading from mipmaps, its generating them manually in the first place. I know I can set a TOP’s sampling mode to mipmap. This works fine, but doesn’t give me control over how I down-sample, blur, etc.
I’m pretty green still with compute shaders and c++. I’ve poked around a bit with those, but not had much luck. Compute shaders seemed promising for generating atlas mip maps, but I kept running into the issue of work groups trying to load data that had not been written yet, etc.
I’m curious if I’m chasing performance gains that can’t be had… or if it may be possible to get faster results.
Goal
Real-time mipmapping of a render pass for generating Bloom and using it in other post process FX.
Attempts
GLSL 1-pass Atlas MipMap
( 0.07ms cpu / 0.05ms gpu / 15 mb gpu )
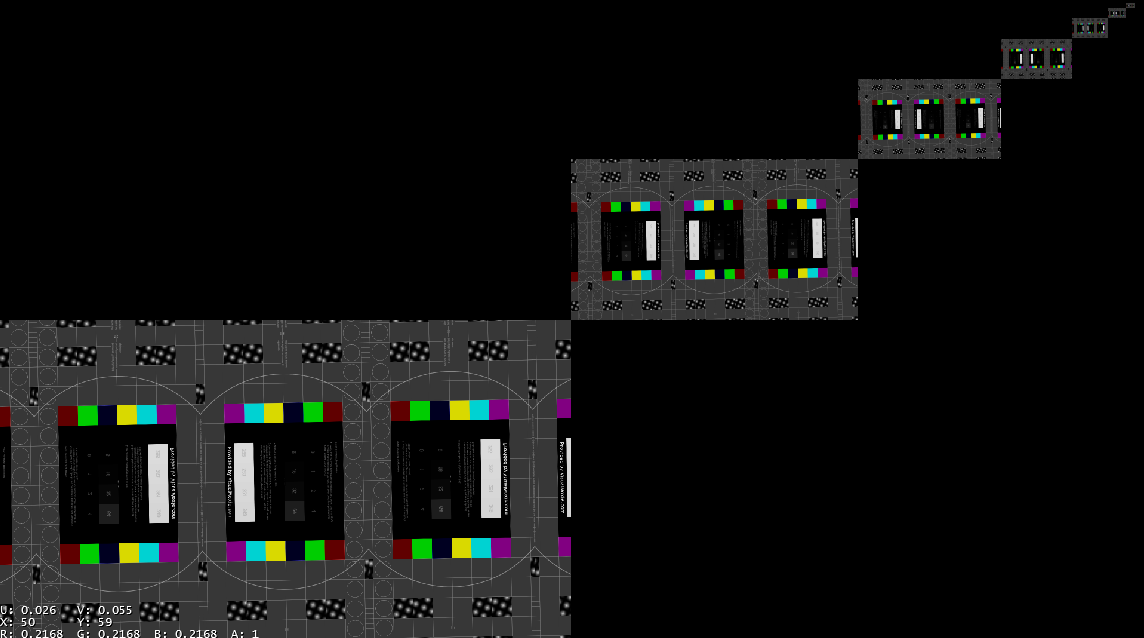
I lifted this technique from an excellent shader toy here.
This seemed like a magic bullet at first due to it’s speed. However. it’s super fast because it’s technically doing the mip mapping wrong. It’s sampling from the input texture and generating all of the mips from input mip0. If you use textureLOD() it can achieve the desired result… However then it negates the purpose of doing it in an atlas anways.
I noticed when using this for bloom, really sharp bright highlights failed pretty badly, and the upsampling mechanism (which I’m not including here but you can see in the shadertoy) produced some very noticeable artifacts:

The problems with the approach stem from the fact that it’s not doing the blurs between iterative mip passes… it tries to blur the entire atlas after the fact.
Node Multi-pass MipMap
( 0.82ms cpu / 0.38ms gpu / 27.65 mb gpu )


This was the easiest to setup, it’s also the least efficient, primarily as far as cpu goes.
The nice thing about this approach is I can use nodes or glsl tops to handle each down sampling pass, so it’s really easy to get in there and do custom shader work between any two mips. It’s also a really convenient format for injecting my own totally different tops from disk, or wherever into any stage in the mip chain. Useful if I want to bring in mips from another software for example (static images)
However this is a bit harder to manage when it comes to varying resolutions and aspect ratios. need to setup complicated switching networks or connect/disconnect/replicate passes to fit the right number of mip maps.
It also scales the worst, in just about any way due to more nodes/memory.
GLSL TDPass Multi-pass MipMap
( 0.40ms cpu / 0.32ms gpu / 6.2 mb gpu )

At present, I believe this is the winner for me… but I still wonder if it could be faster.
Here I’m doing the same basic thing in the previous attempt, but instead of doing things through different tops, I’m leveraging the glsl TOP’s TD Passes functionality to iterate on itself, taking the input of the previous pass, and mipping that.
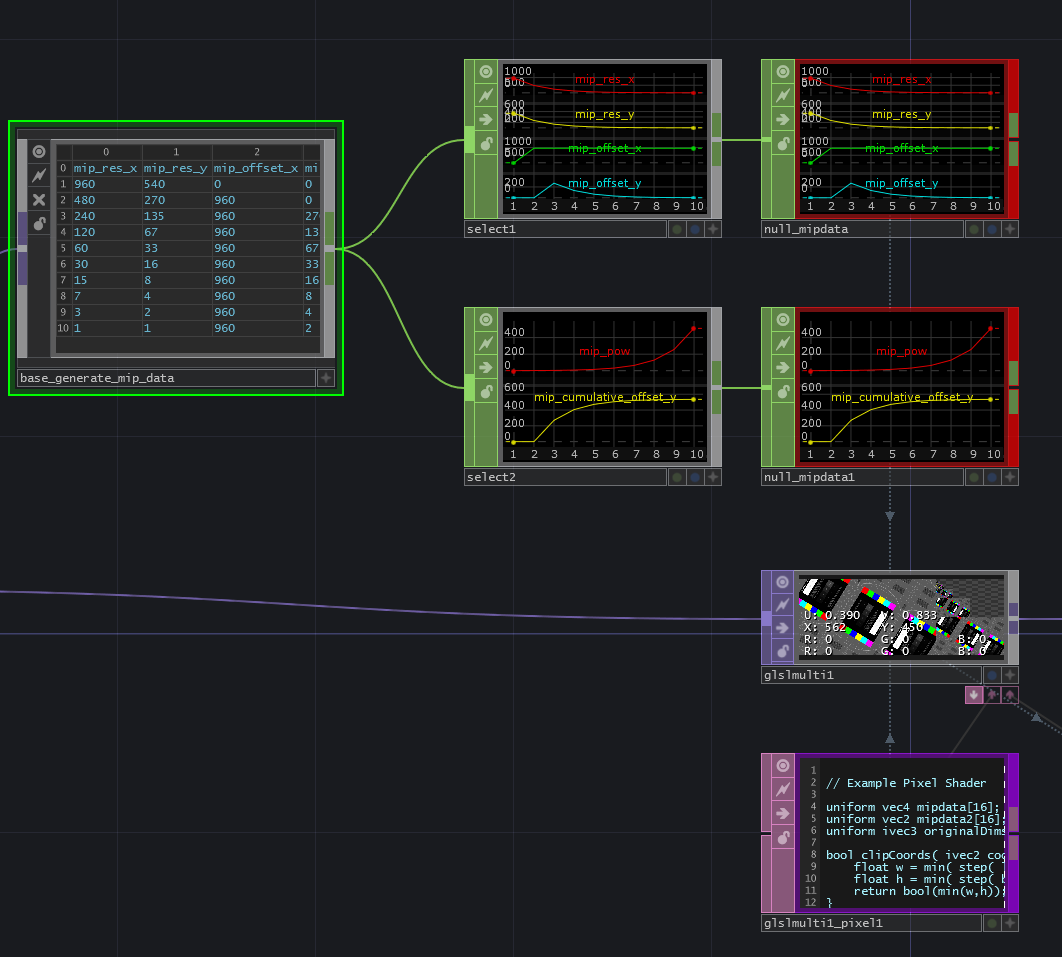
The bottleneck across most of these solutions but especially this one feels like a bandwidth issue. The cost I think comes with the fact that each pass, I first have to copy over the entire buffer 1:1, then process the mips for the current pass, and add that to the results.
This means that if I’m mipmapping a 1080p texture, that’s 11 levels, and 11 times that I sample a full HD res texture. I don’t know how to get around this fact with out something that does less sampling. If you then add even a modest gauss blur between mips, and consider each mip level’s sampling that goes on, it’s a lot more than 11x. maybe 13, or 15x. maybe more depending.
I’m doing some branching in shader to improve this quite a bit… but it’s not clear how close or far that puts this method to whatever the inherent hardware accelerated mipmap generation is.
Any suggestion or ideas for compute shaders? or ++ top?
Thanks!