Hello,
Anyone used libtorch in a c++ operator with visual studio ?
The .dll is generated, but TD do not load the plugin…
Thanks
Hello,
Anyone used libtorch in a c++ operator with visual studio ?
The .dll is generated, but TD do not load the plugin…
Thanks
Can you give bit more info please? Are you creating a top or chop or ? What error is TD throwing you? Are you making a custom op or a c++ op?
Need more info if we are to help.
Hello Mouren,
I’m creating a Top (with Cuda in/out, but i’ll replace it by an OpenGL Top), i want to use libtorch directly with textures.
When I generate my Top without Libtorch on visual studio all is ok. C++ Top works fine.
When i only add #include “Torch/torch.h”, generation on visual studio (2015) is ok, no error,
but the C++ Top can not load the .dll.
Thanks Mouren
Sounds like you are missing the Libtorch dll that corresponds to the libs you included during linking.
You need to place those in your PATH or right next to your new C++ dll.
Thanks Mouren,
Yes I put all the .dll files in the path of my new C++ dll…
I am not with my computer, but I should try generating a “hello world” .exe under openframeworks to verify all is ok.
I tried adding pytorch to the CPUMemoryTOP project but got stuck in the same way.
Start Locally | PyTorch ← 1.4, windows, libtorch, c++, CUDA 10.1
Loading a TorchScript Model in C++ — PyTorch Tutorials 2.0.0+cu117 documentation
Integrating Pytorch c++ (libtorch) in MS Visual Studio 2017 | by BoonBoon Tongbuasirilai | Medium
I’ve copied all the torch dlls into the same folder as my PyTorchTOP.dll. Adding #include <torch/torch.h> makes the DLL not load. I wasn’t sure it was necessary but I also copied from “C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin”
My toe file is set to have the C++ TOP already open at launch. This is the visual studio console when I stop the debugger:
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\PyTorchTOP.dll’. Symbols loaded.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Windows\System32\vcruntime140_1.dll’.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\c10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\torch.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\cusparse64_10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\curand64_10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\cusparse64_10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin\curand64_10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\torch.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\c10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Windows\System32\vcruntime140_1.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\PyTorchTOP.dll’
I tried again by destroying my “C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1” (drastic move) and installing pytorch with conda. Now it’s this:
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\PyTorchTOP.dll’. Symbols loaded.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\c10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Windows\System32\vcruntime140_1.dll’.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\torch.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\nvToolsExt64_1.dll’.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\cusparse64_10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\curand64_10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Loaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\cufft64_10.dll’. Module was built without symbols.
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\nvToolsExt64_1.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\cusparse64_10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\curand64_10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun.conda\pkgs\cudatoolkit-10.1.243-h74a9793_0\Library\bin\cufft64_10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\torch.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\c10.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Windows\System32\vcruntime140_1.dll’
‘TouchDesigner099.exe’ (Win32): Unloaded ‘C:\Users\davidbraun\Documents\Github\PyTorchTOP\PyTorchTOP\Release\PyTorchTOP.dll’
https://pytorch.org/cppdocs/installing.html#minimal-example
I just need to integrate the suggested CMakeLists.txt with the pre-existing CPUMemoryTOP solution. Any Visual Studio user who can help?
Hi,
I just tried again and still same problem, with the include torch.h, the dll don’t load in TD.
I succeeded running a console app with matrices multiplier as a “Hello World”, that works…
I didn’t tried since 2 monthes, i use opencv dnn with cuda to fast style transfer and face landmarks.
I don’t know if all is possible with opencv, i did not learn enough neural networks yet.
Thanks for checking.
I used GitHub - pavelliavonau/cmakeconverter: This project aims to facilitate the conversion of Visual Studio to CMake projects. to turn the starter CPUMemoryTOP into a Cmake. Then I made some changes and I think the CMake side of things is working. It makes a solution and I can build the solution. I manually checked the property sheets of the project, and they look good. They’re being properly set by the cmake boilerplate suggested by pytorch.
GitHub - lucasg/Dependencies: A rewrite of the old legacy software "depends.exe" in C# for Windows devs to troubleshoot dll load dependencies issues. doesn’t show any missing dependencies. All the DLLs seem to be right next to my custom PyTorchTOP.dll. But the dll fails to load in TD.
Update:
also tried using experimental version of TD because it uses CUDA 10.1 and Python 3.7. Didn’t work…
VERY GOOD NEWS!
I used the dependency walker earlier, opened torch.dll rather than pytorchtop.dll and saw that there might be an issue with libiomp5md.dll.
I extracted TD 2019.37030 to a safe folder. Then in that folder I took the libiomp5md.dll from libtorch and overwrote the one inside the experimental build’s bin folder. Now I can run
#include <torch/torch.h>
#include <torch/script.h> and
module = torch::jit::load("traced_resnet_model.pt");
:360 jump emoji: ![]()
![]()
![]()
Yes very good news !
I will try with my official version.
Just info concerning cuda version of Td. It is the version used internal and with the cuda top, but c++ lib torch operator should work with official td version.
For example, I use opencv 4.2 with cuda 10.2 for a c++ top fast style transfer and it’s working with official td version
I have style transfer working in a C++ TOP. It’s with these models: examples/fast_neural_style at main · pytorch/examples · GitHub
In python export the model:
traced_script_module = torch.jit.trace(style_model, content_image) traced_script_module.save("traced_model.pt")
I’m getting 8fps at 1280x720 on my RTX 2080. 640x360 was about 38fps. Hopefully there will eventually be better ways around the CPU<=>GPU stuff that we still need to do.
Good
As soon possible, I will try. I’m curious, my opencv version, in 1280x720, is running at 2 or 3 FPS and in 640x360, 6-8 FPS on my gtx 1060.
Did you find a c++ code or did you translate a python code ?
I tested your solution, it’s working fine.
For the moment, i just did a matrices multiplication, it’s ok…
Version 2019.20140 of Td, with Libtorch 1.4 and Cuda 10.1
at::Tensor tensordata= module.forward(inputs).toTensor().to(torch::kCPU);
Then based on Iterating over tensor in C++ - #2 by Matej_Kompanek - C++ - PyTorch Forums
float* ptr = (float*)tensordata.data_ptr();
// iterate by each dimension
for (int colorChan = 0; colorChan < tensordata.sizes()[1]; ++colorChan)
{
for (int y = 0; y < tensordata.sizes()[2]; ++y)
{
for (int x = 0; x < tensordata.sizes()[3]; ++x)
{
//float* pixel = &mem[4 * (y * width + x)];
//pixel[colorChan] = (*ptr++)/255.;
mem[4 * (y * width + x)+ colorChan] = (*ptr++) / 255.;
}
}
}
for (int y = 0; y < height; y++)
{
for (int x = 0; x < width; x++)
{
float* pixel = &mem[4 * (y * width + x)];
// RGBA
//pixel[0] = 0.;
//pixel[1] = 0.;
//pixel[2] = 0.;
pixel[3] = 1.;
}
}
I think that’s fastest but it’s still CPU heavy. .to(torch::kCPU) is necessary. Also turning the TD input texture into inputs in the first place is a CPU operation…
Ok
In fact with opencv I do these manipulations with cv::mat functions.
Could you post the code how you treat the input model and process functions ?
Thanks
I was cleaning up the code but got distracted because now I think pure GPU is possible if we use the TD’s CUDA C++ example project.
in python modify “fast_neural_style\neural_style\neural_style.py”
traced_script_module = torch.jit.trace(style_model, content_image)
traced_script_module.save("udnie_1280x720.pt")
Run:
python neural_style/neural_style.py eval --content-image test640x360.jpeg --model saved_models/udnie.pth --output-image myoutput.png --cuda 1
in C++:
module = torch::jit::load("udnie_1280x720.pt");
at::Device device = at::kCUDA;
at::Tensor reuse_tensor = torch::ones({ 1, 720, 1280, 4 }, device = device);
reuse_tensor.copy_(torch::from_blob(videoSrc, { 1, 720, 1280, 4 }, tensorOptions));
//std::cout << reuse_tensor.sizes() << '\n';
torchinputs.clear();
// The thing we push back must be of format {1, 3, 720, 1280} because it's 1 image, 3 color channels, 720 rows, 1280 columns
// Since we're starting with something that's {1, 720, 1280, 4},
// we'll first narrow the last dimension to three channels rather than 4.
// Then permute.
torchinputs.push_back(reuse_tensor.narrow(3, 0, 3).permute({ 0,3,1,2 }));
// torchinputs.push_back(torch::ones({ 1, 3, 720, 1280 }, device = device).to(torch::kFloat32)); // fake data
// Execute the model and turn its output into a tensor.
// Putting it on the CPU at the end is what allows us to access values with a pointer.
at::Tensor torchoutput = module.forward(torchinputs).toTensor().div(255.).to(torch::kCPU);
torchinputs.clear();
fillBuffer(mem, output->width, output->height, torchoutput);
and:
void
PyTorchTOP::fillBuffer(float* mem, int width, int height, at::Tensor tensordata) {
//std::cout << "size " << tensordata.sizes() << '\n';
float* ptr = (float*)tensordata.data_ptr();
// iterate by each dimension
for (int colorChan = 0; colorChan < tensordata.sizes()[1]; ++colorChan)
{
for (int y = 0; y < tensordata.sizes()[2]; ++y)
{
for (int x = 0; x < tensordata.sizes()[3]; ++x)
{
mem[4 * (y * width + x)+ colorChan] = *ptr++;
}
}
}
for (int y = 0; y < height; y++)
{
for (int x = 0; x < width; x++)
{
mem[4 * (y * width + x)+3] = 1.; // optimized for just making alpha=1.
}
}
}
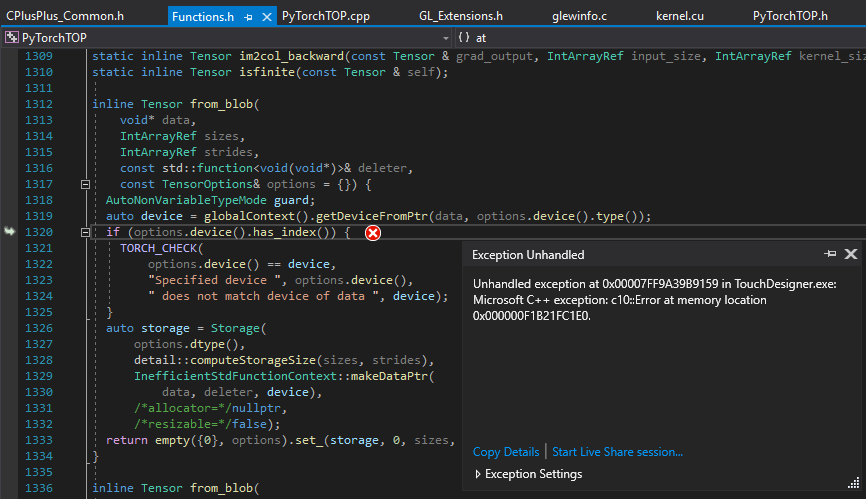
Now I want to use torch::from_blob with the CUDA C++ example. It’s failing on
auto inTexTensor = torch::from_blob(topInput->cudaInput, { 1, 720, 1280, 4 }, tensorOptions);
Thanks very much for the code David.
I’ll try it as soon as possible.
I think the problem with from_blob, the same as readfromblob in opencv, is that they only accept images on cpu.
I follow opencv dnn dev, and apparently it will be soon possible to use Gpumat in input…
I was hoping from_blob could handle either case. You would just need to specify kCUDA
and
and from earlier (this seems like overkill because it’s running python inside c++ with boost)