Python Tips’N’Tricks
4 Likes
Excellent! Absolute gems in here.
Figured I’d contribute a couple other neat ones I use a lot:
op("someDat").col('columnName')[1::]
This returns a list of table cells. using [1::] at the end omits the first row, which is useful if that is a header and not usable data.
This gets even better if you are trying to supply a join CHOP for instance with a list of space separated op paths. you can use the above one liner with great success.
If you need the values of those cells as strings for instance, map() is great:
list( map( str , op("someDat").col('columnName')[1::] ) )
Or if you have a table column of op paths, then map can help turn those into op references:
list( map( op , op("someDat").col('columnName')[1::] ) )
Another one that is great - somewhat hard to read, but can be invaluable in a pinch is the one liner for taking a 2 dimensional array and “unraveling” it into a 1 dimensional array:
# traditional double for loop structure:
for word in sentence:
for character in word:
character
# Oneliner for double list comprehension.
flattenedWordList = [character for word in sentence for character in word]
3 Likes
So many great tricks.
In general, I put anything I write that I think might be useful in TDFunctions, so check this out: TDFunctions - Derivative
Also want to give specific attention to tdu.split. This function is used to facilitate space separated lists in string parameters. It returns a list of the items in the string, and obeys quotes. So: tdu.split(‘a b c “d e”’) returns [‘a’, ‘b’, ‘c’, ‘d e’]
Super useful if you want to put a list of items in a custom string parameter.
2 Likes
Oh yeah, the whole [:1] [1:] [-1] structure is def worth an entry!
The mapping ones also look really intriging, esp the map to op might be incredible usefull!
In all thinking if this should be a series of posts or if I should edit new ones into the main post.
Im currently more leaning towards a series with small peaces for better digestion.
What do you think?
ya for sure! series or single, not sure - maybe if multiple can just cross link between them so anyone who stumbles on one can find the rest in the series? This is seriously a great topic. great idea you had here.
some link in every entry pointing to the prevoius and the next entry. Should be doable ![]()
1 Like
Thanks for nice tricks ![]()
I would like to ask whether it wouldn’t be better to just use op('opname').pars('parname')[0] instead of those has/get/set attrs?
Yes, this is not good. No problem to use in simple one off events, but in general not the best solution. You are basicly handpicking a single element out of a list of all the parameter. I suppose this gets slower the more pars you have.
The fastest way is in fact to have the refference stored once and acces the object directly.
Nearly the same is setattr and getting the attribute and setting then the value.
Usinf your equasion sadly bombs completly ![]()
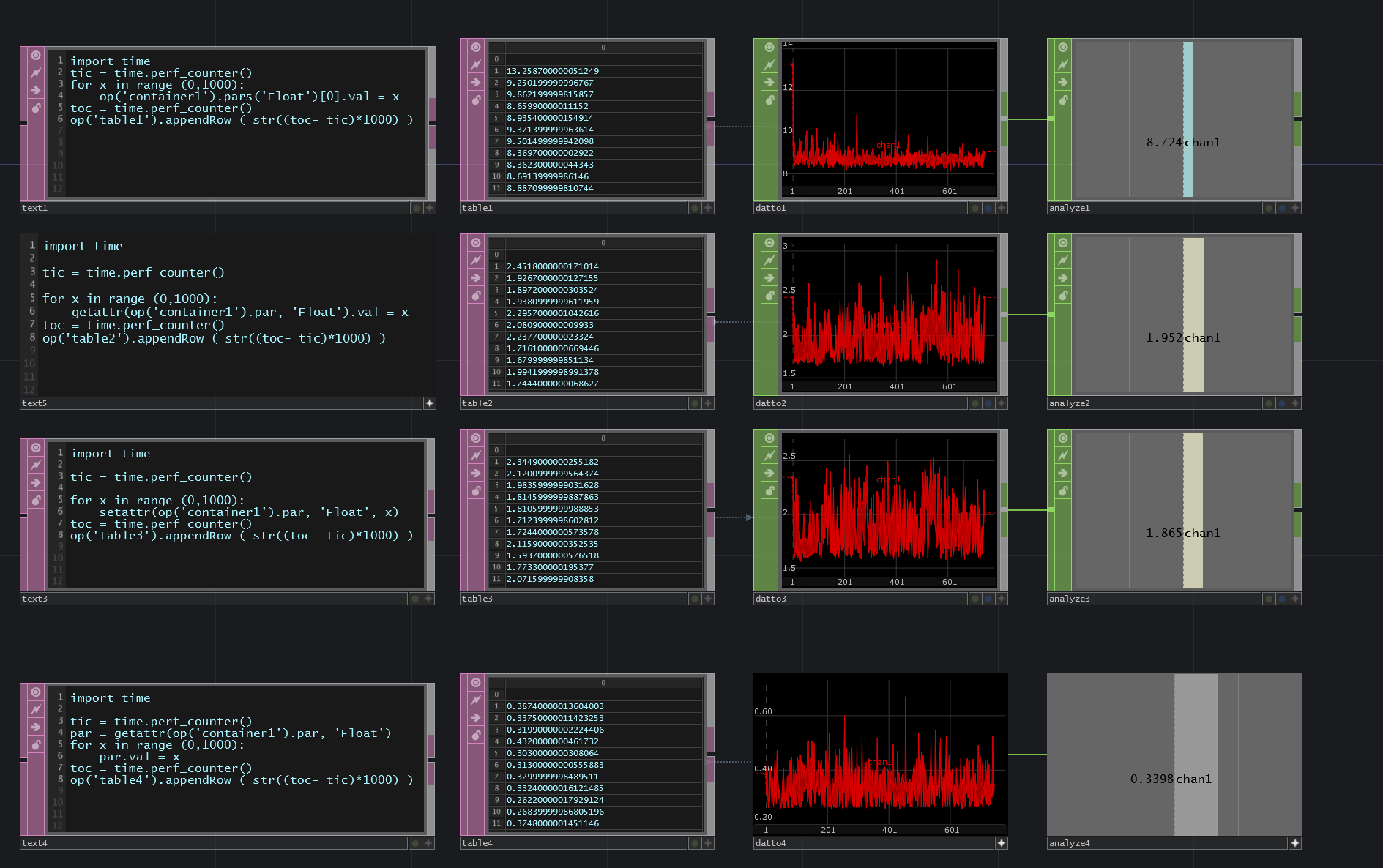
2 Likes
Aha, I see. Thank you very much for this performance comparison.
Maybe this kind of functionality could be added in new method so that newcomers could easily find it and use it? I mean it would make sense to be able to do something like op('opname').getpar('parname') (with essentially the same performance as with getattr).
For example in Houdini one could do the same thing with hou.node('nodename').parm('parname'). I think it makes the code more clean and readable. What do you think?
In theorie totaly with you here!
I think the fastest would be if the par member could just be a dictionary of all the parameters. Kinda nobrainer that it isn’t … (so it would be op().par[‘Float’]. Floating arround in my head for a while now, gonna open an RFE.
1 Like
That sounds great, I hope it will be implemented at some point.
Ya agreed, params get expensive when accessing them from scripts in large numbers or real time. Have also gone that route of storing param refs in python storage of some kind, and it does speed things up a lot.
Well, that’s something I love about deriative. One small question can lead to change real quick:

4 Likes
Wow, this is great, I didn’t expect it to be implemented this fast. Thanks! ![]()
I’m excited about this too! To be clear, it will be par[‘Parname’] not par[‘Parlabel’]
There will never be an op(‘base’).par[‘MyFloat’]! It would be op(‘base’).par[‘Myfloat’]
1 Like
You can use anything to be the value of dict, but not the key. Dictionary is a hashtable, so every key should be hashable object, i.e. it should be unchangeable, so you can use integers, strings, booleans and some other objects as a key, but if you try to use, for example, list as a key you’ll get “TypeError: unhashable type: ‘list’”, so you’ll need to keep that in mind.
1 Like
Thanks for the additional Info: Did some testing and in fact lists do not work. But classes and objects can otherwise be used (Suppose because we are using the pointer to the object as the key instead of the object itself, same for functions), which does not work for lists. But we can use tuples instead of a list so a similiar result.

Yeah you’re not allowed to use any object that is mutable. Lists, sets, and dicts are the obvious examples of non-hashable objects.
Added a little note regarding that. Thanks for the info ![]()
The new f-string format is worth learning for anyone doing text work. Faster and cleaner than any previous Python method for inserting data into strings.
1 Like