Hello every body, I want to know why in some architecture, there is fully connected layers at middle of network?
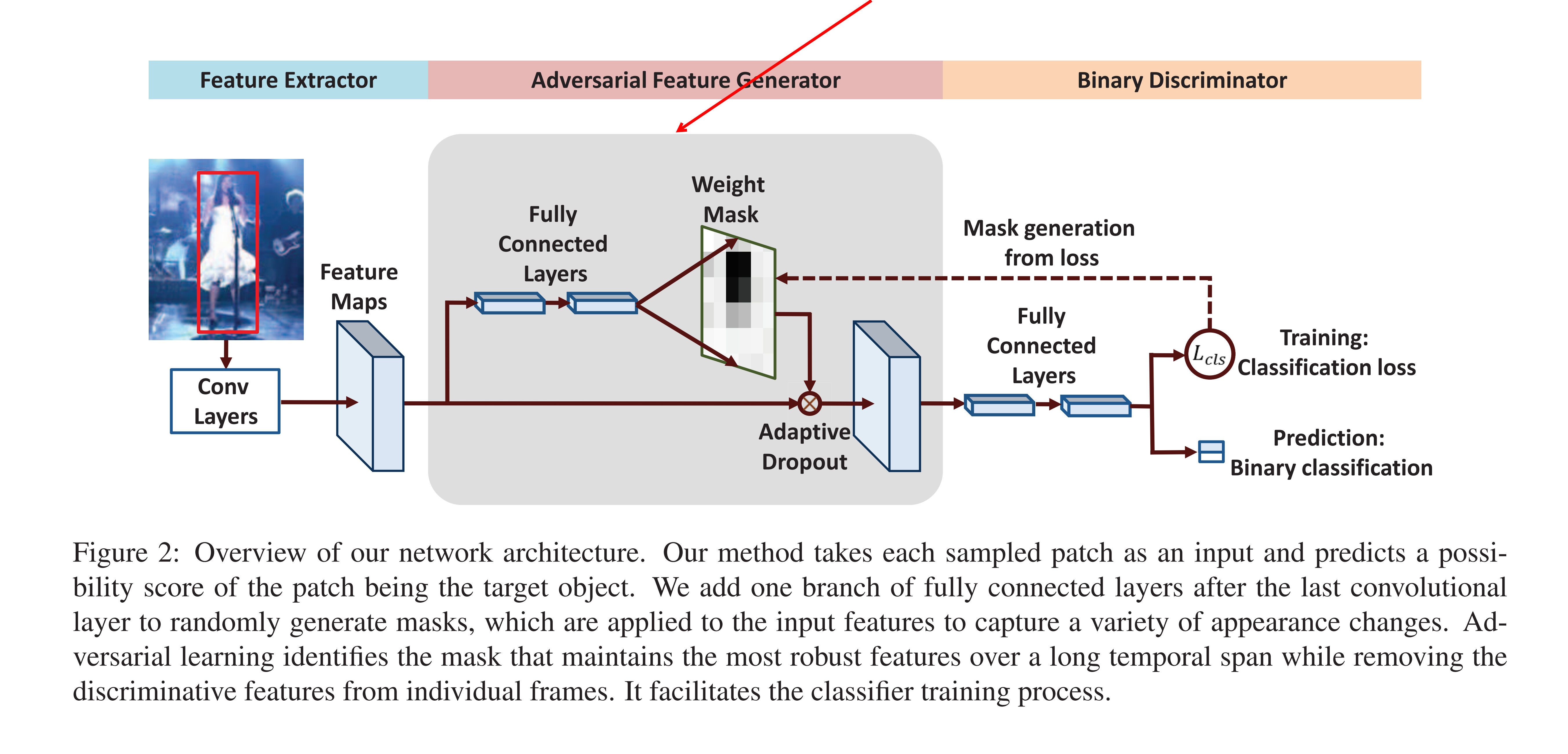
for example in this architecture used as object tracking, the aims is to products the mask that has the robust features on temporal span.
@timgerritsen and @Darien.Brito might be able to give their grain of salt on this one. Decoding CNNs is an interesting - but quite advanced - topic!
1 Like
I’m definitely no expert in those model architectures, but what I think why they are there is to make final detailed connections to produce the high resolution end result. Some networks uses a 1x1 convolution to have a similar result I think. The problem with those layers is that it takes too many neurons to capture all data (very hard to train and to compute), where convolutional layers learns filters/kernels, little ‘re-useable patches’ used over the whole image, but hard to capture the details, so merging them would make sense.
2 Likes
Take face recognition for example. The convolutional layers at the beginning do basic edge detection. The subsequent layers do stuff like finding edges at certain angles or finding curtain curves. As the convolutional layers get deeper, they become detectors for building blocks of the face like eyes, mouths, and noses. None of that is explicitly programmed. It just emerges from the architecture of the neural network and the data. I would google Histogram of Oriented Gradients (HOG) for some historical context. People used to manually specify the parameters of the convolutions and then use an SVM classifier. Now people use convolutions whose parameters get learned over time and then fully-connected layers instead of SVM.
If you want to read a book on it, I recommend “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems 2nd edition”. I also recommend Stanford’s CS 231N on Youtube.
4 Likes